
Description
In this project, we will work with real-life data provided to us by Bertelsmann partners AZ Direct and Arvato Finance Solution. The data here concerns a company that performs mail-order sales in Germany. Their main question of interest is to identify facets of the population that are most likely to be purchasers of their products for a mailout campaign.
Our job as a data scientist will be to use unsupervised learning techniques to organize the general population into clusters, then use those clusters to see which of them comprise the main user base for the company. Prior to applying the machine learning methods, we will also need to assess and clean the data in order to convert the data into a usable form.
Goal:
Look at relationships between demographics features, organize the population into clusters, and see how prevalent customers are in each of the segments obtained. Check My - Jupyter notebook.Compare Customer Data to Demographics Data
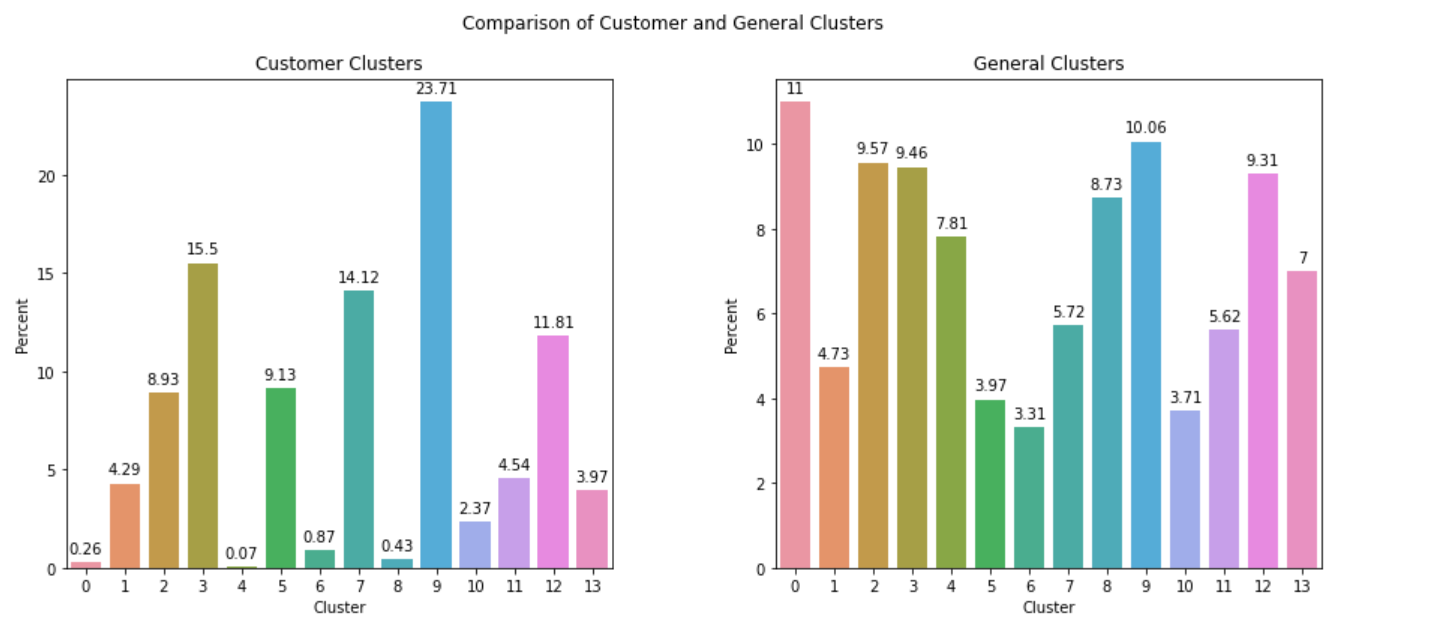
By looking at the graph we can easily find that the cluster points 3, 5 and 7 data points are highly likely customer segments because the larger praportion of customer data is present at these points while data points that are defined by cluster points 0, 4 and 8 are less likely to be turned into customers are general population data dominates these clusters.
Cluster 7 is overrepresented in the customers data compared to general population data, we can describe some segments of the population that are relatively popular with the mail-order company:
Cluster 0 is underrepresented in the customers data compared to general population data, we can illustrate some segments of the population that are relatively unpopular with the company: